
”spark hadoop“ 的搜索结果
人工智能-hadoop
wind7 /win10 hadoop 2.7.7 配置 winutil 直接解压后copy到hadoop/bin目录就可以了
Hadoop是Apache旗下的一个用java语言实现开源软件框架,是一个开发和运行处理大规模数据的软件平台。允许使用简单的编程模型在大量计算机集群上对大型数据集进行分布式处理。HDFS(分布式文件系统):解决海量数据...
主要用于pyshon 对spark 大数据开发使用

MapReduce是一个分布式运算程序的编程框架,核心...快速Spark 使用DAG执行引擎以支持循环数据流与内存计算,其在内存中的运算速度是 Hadoop MapReduce运行速度的 100 多倍,在硬盘中是 Hadoop MapReduce的 10 多倍。
Spark框架包含多个紧密集成的组件,包括Spark SQL(即席查询)、Spark ...4、随处运行:用户可以使用Spark的独立集群模式运行Spark,也可以在亚马逊弹性计算云、Hadoop YARN资源管理器或Apache Mesos上运行Spark。
通常情况下,Apache Spark运行速度是要比Apache Hadoop MapReduce的运行速度要快,因为Spark是在继承了MapRudece分布式计算的基础上做了内存计算的优化,从而避免了MapReduce每个阶段都要数据写入磁盘的操作,这样就...
文件名: spark-3.4.1-bin-hadoop3.tgz 这是 Apache Spark 3.4.1 版本的二进制文件,专为与 Hadoop 3 配合使用而设计。Spark 是一种快速、通用的集群计算系统,用于大规模数据处理。这个文件包含了所有必要的组件,...
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。Storm是一个分布式的、容错的实时计算系统。两者整合,优势互补。
Spark 生态圈是加州大学伯克利分校的 AMP 实验室打造的,是一个力图在算法、机器、人之间通过大规模集成来展现大数据应用的平台。AMP 实验室运用大数据、云计算、通信等各种资源及各种灵活的技术方案,对海量不透明...
新的spark版本,增加了新的功能,欢迎大家下载使用!!!
1.安装Hadoop和Spark进入Linux系统,完成Hadoop伪分布式模式的安装。完成Hadoop的安装以后,再安装Spark(Local模式)。2.HDFS常用操作。
Hadoop 是一个提供分布式存储和计算的。
apache-hive-3.1.3-bin.tar.gz apache-zookeeper-3.5.10-bin.tar.gz hadoop-3.3.3.tar.gz spark-3.2.1-bin-hadoop3.2.tgz mysql-8.0.29-1.el8.x86_64.rpm-bundle
去实习,发现工业界用的大多用这种大数据处理方式。
Spark and Hadoop碎片知识点合集
实际上,Spark已经很好地融入了Hadoop生态圈,并成为其中的重要一员,它可以借助于YARN实现资源调度管理,借助于HDFS实现分布式存储。此外,Hadoop可以使用廉价的、异构的机器来做分布式存储与计算,但是,Spark对...
Hadoop Spark 类型 基础平台,包含计算、存储、调度 分布式计算工具 场景 大规模数据集上的批处理 迭代计算,交互式计算,流计算 价格 对机器要求低,便宜 对内存有要求,相对较贵 编程范式 Map+Reduce,...
Spark高清hadoop
标签: spark
图解Spark 核心技术与案例实战,很好的学习资源,希望大伙喜欢!
这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)**[外链图片转存中…(img-KjSEvey2-1712528382648)]
Hadoop 是一个提供分布式存储和计算的。
Spark 单机部署、集群部署 Java 访问 Spark 测试
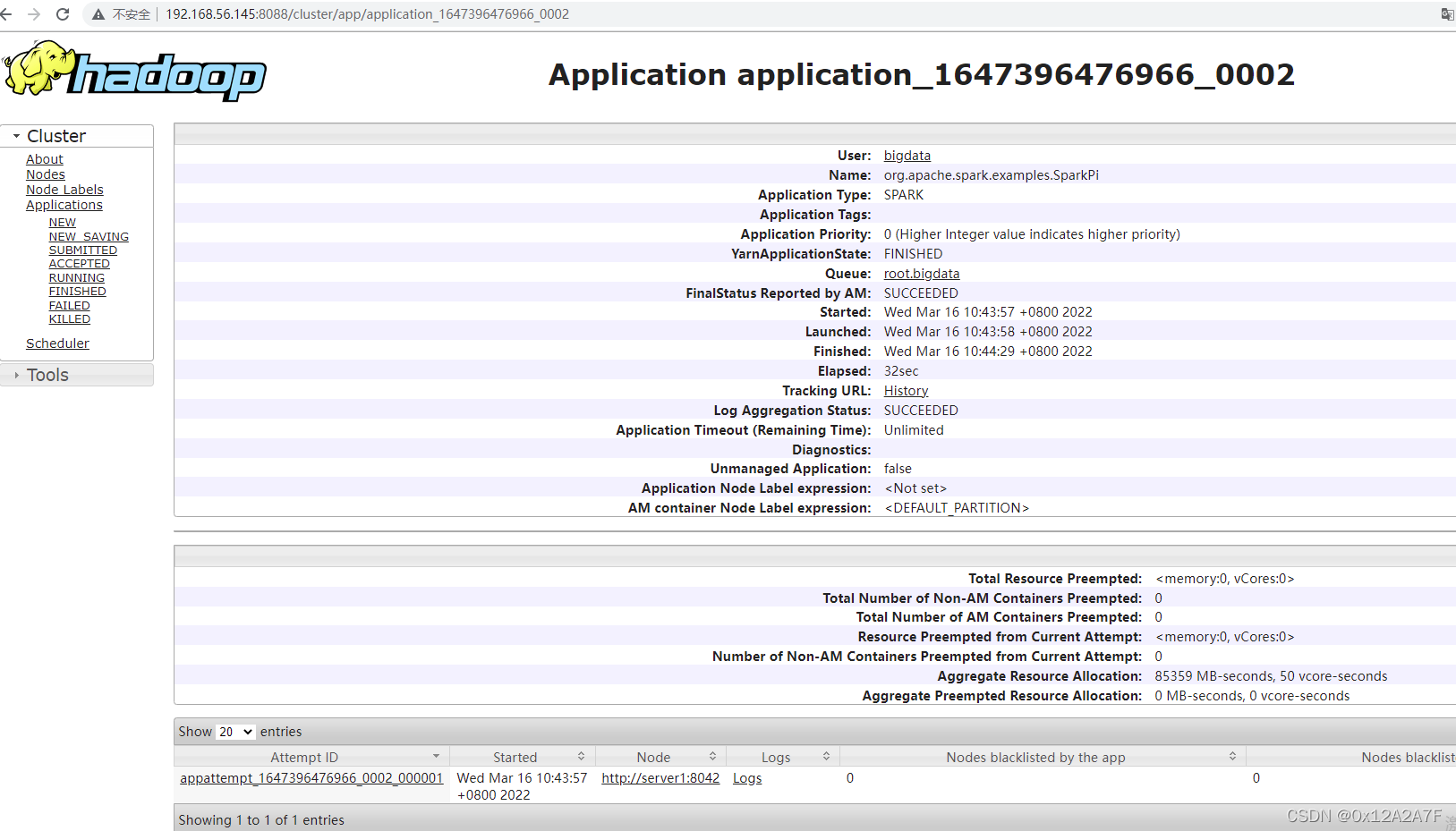
Spark streaming应用运行7天之后,自动退出,日志显示token for xxx(用户名): HDFS_DELEGATION_TOKEN [email protected], renewer=yarn, realUser=, issueDate=1581323654722, maxDate=1581928454722, sequence...

计划做一个s141~s146的分布式。 一、制作基本的docker ...安装完hadoop后,保留为centos7-ssh-hadoop 建立伪分布式,注意参考下面的(1) 配置hadoop配置文件core-site.xml、hdfs-site.xml、ma...
hadoop版本hadoop-2.7.7,spark版本spark-2.2.0-bin-hadoop2.7,搭建步骤如下: 1.配置hadoop的环境变量 F:\bigdatatool\hadoop-2.7.7\bin 修改F:\bigdatatool\hadoop-2.7.7\etc\hadoop目录下的core-site.xml、hdfs...
推荐文章
- Android 编译so文件 MP4V2_android下编译mp4v2-程序员宅基地
- 通讯录Contact_02_contact文件内容-程序员宅基地
- Qt笔记(四十二)之QZXing的编译 配置 使用_qzxingfilterrunnable error:-程序员宅基地
- 关于画图软件Dia打开程序始终为英文界面的问题-程序员宅基地
- OpenCV从入门到精通实战(二)——文档OCR识别(tesseract)-程序员宅基地
- 详解avcodec_receive_packet 11_avcodec_receive_packet eagain-程序员宅基地
- OpenGL SuperBible 7th源码编译记录_superbible7-media github-程序员宅基地
- Wireshark简单使用-程序员宅基地
- MXNet 粗糙的使用指南_iou loss mxnet-程序员宅基地
- iOS对ipa包进行代码混淆《二》 ---代码混淆_ipa包混淆-程序员宅基地